
Nick Boddicker, Ph.D.
Genomics는 심각한 돼지의 유전학 회사에게는 평범한 것이되었으며, 유전 적 이득을 향상시키는 데 사용되며, 이는 고객의 수익성에 직접적인 영향을 미칩니다. 유전자형 정보는 유전체학 및 유전체 선택의 기초입니다. Genotyping은 미리 정해진 마커 또는 SNP (single nucleotide polymorphisms)를 읽는 특별한 "칩"을 사용하여 수행됩니다. 오른쪽에는 상업적으로 이용 가능한 SNP 패널의 두 가지 예가 있습니다. 이 두 패널은 모두 high-throughput genotyping으로 알려진 수만 개의 SNP를위한 96 (1) 또는 24 (2) 동물을 동시에 유전자형화할 수 있습니다. 이 기사에서는 하이 스루풋 유전자 타이핑의 기본 사항과 그 디자인이 최종 사용자의 결과, 즉 유전학 회사에 중요한지에 대해 논의합니다.

genotyping의 첫 번째 부분은 동물에서 샘플을 수집하고 DNA를 추출하는 것입니다. 일반적인 샘플 유형에는 조직 (꼬리, 귀 노치), 모발 (모낭이 있어야 함) 및 혈액이 포함됩니다. 샘플 유형에 관계없이 동물을 성공적으로 유전자형 화하려면 충분한 양의 DNA를 추출 할만큼 충분히 커야합니다.
SNP 패널 설계의 두 가지 측면은 최종 사용자에게 결과에 영향을 미치며, 이들은 게놈과 SNP 밀도에 걸친 SNP의 간격입니다. 밀도는 패널의 SNP 수를 나타내며, 상업적으로 사용 가능한 패널의 경우 수천에서 650 천입니다. 가장 일반적으로 사용되는 SNP 수는 50,000 SNNP와 65,000 SNP 사이입니다. 패널의 마커 수가 3,000 또는 650,000이든, 게놈 평가를 향상 시키려면 마커를 전체 게놈에 균등하게 배치해야합니다. SNP 패널의 거의 모든 마커는 실제 유전자가 아니므로 관심 대상의 특성에 직접적인 영향을 미치지는 않지만 유전자와 관련이 있습니다. 마커가 너무 가깝게 배치되면, 특정 형질에 대한 유전자의 동일한 효과를 식별 할 가능성이 있으며 이는 중복됩니다. 마커 사이의 거리가 너무 멀면 사용자는 해당 유전자에 영향을 미치지 않을 수 있습니다. 왜냐하면 마커가 관심있는 유전자와 "연결"하기에 충분하지 않기 때문입니다. 따라서 패널의 밀도가 낮을수록 마커는 전체 게놈을 스패닝해야합니다.
마지막으로, SNP의 품질이 중요합니다. 각 SNP는 대립 유전자 (A와 B)로 알려진 두 개의 "상태"를 가지며 대립 유전자는 SNP의 유전자형으로 알려진 세 가지 다른 조합 (AA, AB 및 BB)을 형성 할 수 있습니다. 컴퓨터가 SNP 패널을 분석 할 때, SNP의 각 대립 유전자는 독립적으로 정량화되고 "강도"값으로 표시됩니다. 동물의 그룹에 대해 두 강도 값을 서로 대입 할 때, 구별되는 그룹이 있어야합니다. 이러한 그룹은 유전자형입니다. 아래는 949 Genesus 동물을 사용하여 양질의 SNP의 예입니다. 이 경우 수평 그룹핑 (파란색)은 유전자형 AA이고 수직 그룹화 (녹색)는 BB이며 대각선 그룹화 (빨간색)는 각 대립 유전자 중 하나 또는 AB를가집니다.
최근 몇 년간 새로운 기술로 최종 사용자는 SNP 패널을 "사용자 정의"할 수있었습니다. SNP 패널을 사용자 정의하면 최종 사용자는 패널의 표준 SNP 외에도 모집단과 관련된 SNP를 포함 할 수 있습니다. 수년에 걸쳐 Genesus는 수만 마리의 동물을 유전자형으로 분류하여 그 개체군에서 중요한 SNP를 확인했습니다. Genesus는 최근 genotyping 회사와 협력하여이 SNP를 우리 게놈 평가에 사용될 맞춤형 패널에 통합했습니다. 이러한 맞춤형 SNP는 사료 섭취, 성장, 모돈 수유 효율, 육질 및 PRRS 및 PCV2 탄력성과 같은 인구 건강과 같은 핵심 경제적 특성과 관련됩니다. 55,000 SNP가 포함 된이 사용자 정의 패널은 유전 적 이득을 증가시키고 궁극적으로 Genesus 고객의 수익성을 향상시킵니다.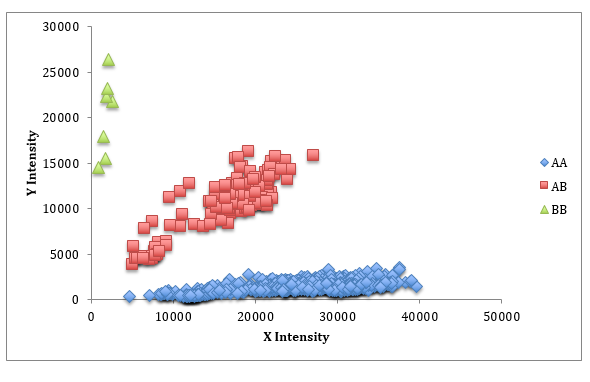



{kind=link}
이 게시물은 Genesus에 의해 작성되었습니다